Kahba: automating the browser
The Kahba API offers tools and control flows that let us write sophisticated, multi-page automations, built
up from smaller automations.
But first... the name. It sounds weird so an explanation: Kahba is a combination of two ancient Egyptian words relating to the afterlife:
kah and ba. Just as a web page's kah departs when the browser navigates away, some of its ba lives on to continue its spiritual quest.
So not a weird name at all.
Kahba lets you write control flows that survive browser navigation.
Consider this Kahba control flow:
kahba.eachSeries(urls,
kahba.waterfall([
runner.visitThePage(),
figureOutWhatChanged,
promptUserToAct,
updateOurInternalWebForm
]));
The above iterates over a variable list of URLs, with eachSeries and waterfall behaving much like their popular asyncjs
cousins. It points the browser to each page in the list one at a time, working on a sequence of tasks once there, tasks
that each have simple jobs of their own. The instructions are written as a single, seamless control flow, even though they direct the browser to navigate.
Kahba helps you break up complicated web-based integrations into small, reusable components.
In this tutorial, we'll familiarize ourselves with some of Kahba's control flows, learn how they nest together, and explore features
that make building web automations more productive.
Example project
For our example project, we'll write an automation that helps users with recurring e-commerce purchases. We'll write it with a
team in mind, one that collaborates together on what to buy using a shared product list. When run, our automation will read the
list and help buy the items online.
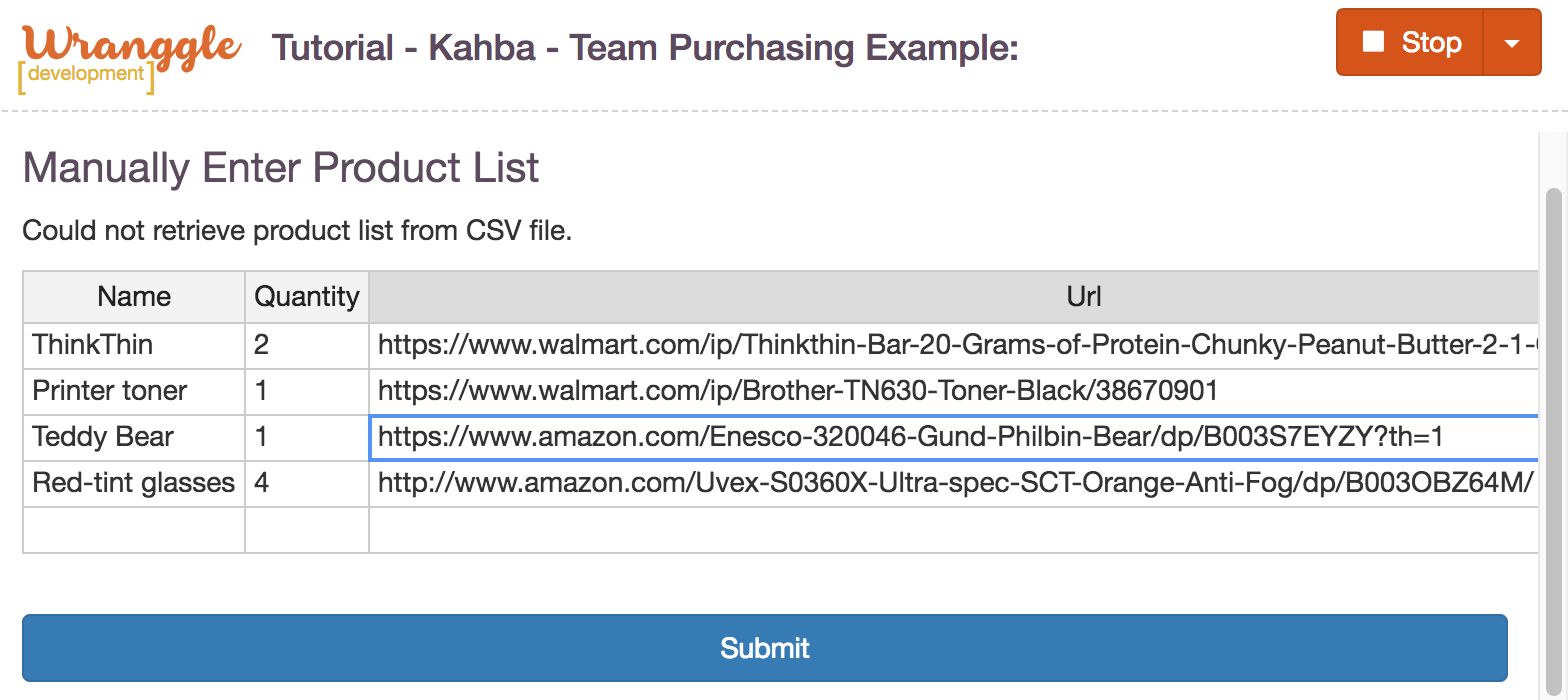
This tutorial uses a CSV file on Github as its database, holding the list of products that need to be purchased. We use a file on Github
only because it's convenient in the context of a tutorial, in that it's accessible without requiring any sort of account creation but
if you already have a Github account, as is likely, you'll be able to fork the file if you feel like making changes. Swapping Github
out for a different service/site is quite straightforward.
Project setup
We start with partially-written project files:
-
Download the tarball: wranggle-kahba-tutorial.tar
-
Expand it tar xf wranggle-kahba-tutorial.tar and cd into the project directory
-
Install its dependencies:
# eg:
yarn install
# or:
npm install
-
Verify @wranggle/automation-builder is working:
node_modules/.bin/wranggle version
Run the bundler and wranggle dev server
Our project's package.json includes script shortcuts to run the bundling system, this time using Browserify.
(The Dev Server tutorial uses Webpack, feel free to use any bundler you like in your own automations.)
Before you begin, make sure the automation-builder dev server isn't running for a different automation.
-
In a command line shell, build and watch for changes:
# eg:
yarn watch
# or:
npm run watch
-
In a command line shell, start the automation-builder server:
# eg:
yarn server
# or:
npm run server
-
Ensure your browser accepts the automation-builder's localhost https certificate. After requesting this in your browser,
and accepting its unsigned certificate, you should see json text:
https://localhost:3030/automations/wranggle-automations-registry.json
Kahba control flows
In your IDE, open team-purchasing-example.js, the project entry point. You'll notice it contains a waterfall with each of
its tasks commented out. We'll walk through each of its tasks one at a time, uncommenting them as we go, exploring new Kahba
concepts as we encounter them.
Uncomment the first task in the waterfall: fetchProductList(runner).
You may notice a second iteration of the file is also checked into the project, a file that looks less pleasant than the first. You
can ignore it for now — we'll use it in the "Mastering Control" section to cram in some remaining advanced topics.
Source for fetch-products.iteration-1.js:
const _ = require('lodash');
const { parseCsvAndGroupProductsByHostname } = require('../../support/csv-support.js');
module.exports = function fetchProductList(runner) {
const { kahba } = runner;
return kahba.waterfall([
runner.visit('https://github.com/wranggle/example-github-as-db/blob/master/tutorial-support/product-list.csv'),
runner.wait('.file:visible'),
() => runner.xhr($('#raw-url').prop('href')),
(xhrResponse={}) => {
const productsByHostname = parseCsvAndGroupProductsByHostname(xhrResponse.body);
kahba.stash.productsByHostname = productsByHostname;
return Promise.resolve({ productsByHostname });
},
]);
}
Explanation
Looking at src/workflows/shopping-list/fetch-products.iteration-1.js, we see it builds and returns its own kahba.waterfall. Kahba
includes control flow methods mirroring most of the popular caolan/async library, including
waterfall which passes any output data from a task into the next task as an input.
Using runner.visit, our workflow navigates to a sample/fixture list of products. The URL is currently hardcoded, something we'll
change after covering how variables can be accessed and passed between workflows. Note that this URL doesn't
point to an actual CSV file but to a Github cover page, an html page that renders the csv content into a table with links to version history and such.
The next task calls runner.wait to ensure the page has rendered sufficiently before our waterfall continues. The Wranggle
browser extension runs automation scripts as early as possible on each page, often beginning before the DOM-ready event. We could
wait for DOM ready using runner.wait(true), or pass it multiple conditions that must all complete before it resumes, as jQuery/Sizzle
selector strings, time in ms, or sync functions, eg: runner.wait([ true, 1000, '#raw-url', () => doesPageLookReady() ])). We'll
revisit the topic of waiting later when we intentionally want it to fail early to avoid making the user wait for no reason.
The third task in our workflow fetches the raw csv file contents as a string, calling runner.xhr to make an ajax/XMLHttpRequest
request. It plucks the actual csv file's URL from a DOM element, a link button on the page for viewing the raw file. We could actually
pluck all the product data out of this same page directly but we'll want our workflow to later work with any CSV file, not just ones rendered
into a table for us by Github.
runner.xhr uses the xhr library under the hood, letting us set request headers and such should we
need to. As with most Wranggle-related methods, runner.xhr accepts a callback or, when omitted as it is here, returns a Promise. When
runner.xhr completes, its promise is resolved and our waterfall continues, passing its result into the next task. The XHR library
sets the information we're after, the raw content of the csv file as a string, on xhrResponse.body.
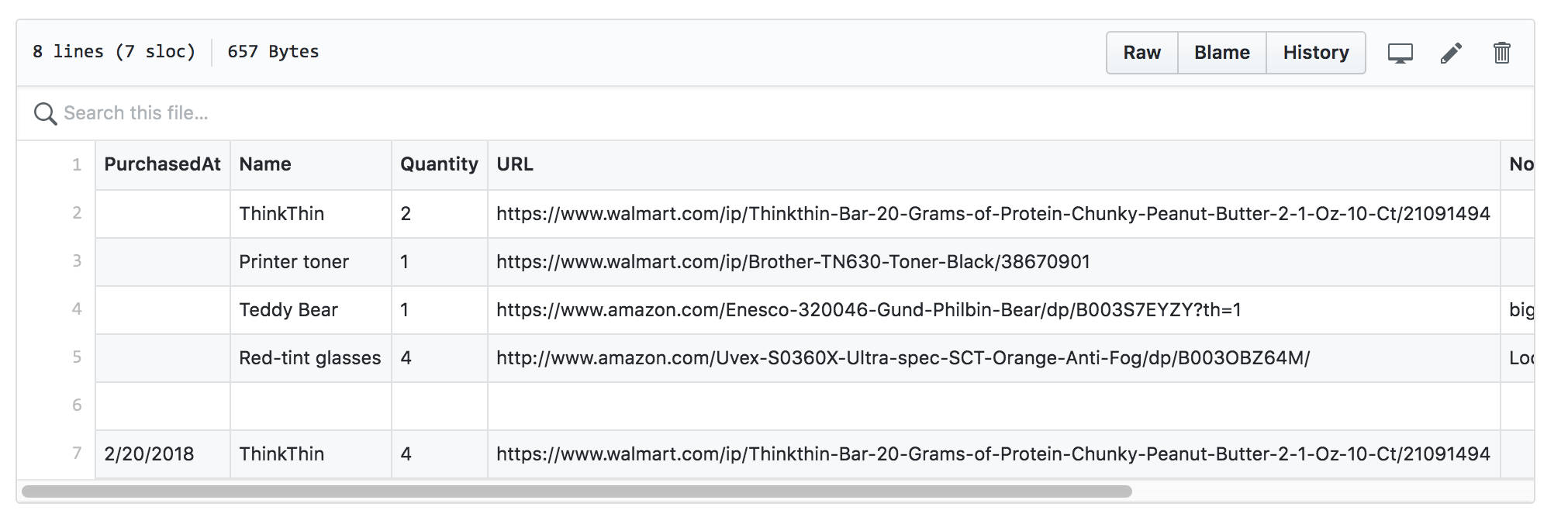
The last task in this workflow calls parseCsvAndGroupProductsByHostname, a support/utility function that parses, filters, and formats the
data. This function does not not contain any Wranggle-specific code, so we won't look at it too closely. The main point of interest is
that it uses an external library, csv-parse, added to our package.json as a normal
node.js dependency. Our support function filters out blank lines, items already purchased, and items missing a valid URL, and
then returns its data in a self-defined/arbitrary format that is convenient to our current project, as an object that groups
products by store, looking like: { hostname: [ product_1, product_2 ] }, where each product item is an object of
{ name, quantity, url, notes }.
The last task returns a promise, one immediately resolved to let the waterfall know it should continue. Alternatively, we could have used
a callback, eg: (xhrResponse, cb) => cb(null, { productsByHostname }) or one of the more powerful kahba.run methods that we'll
encounter later. This task introduces one additional Kahba concept, kahba.stash, covered in the next section.
Parallels to caolan/async
Kahba includes most of the control flow and collection-category methods in caolan/async but
renames some, adding an underscore ("_") suffix to methods that have tempting, innocent-sounding names like "each" yet in
the context of a web automation might lure their victims into running all tasks in parallel when that would be undesireable. Use kahba.eachSeries when
navigation is involved because the browser cannot of course visit multiple pages at once in a tab, but for XHR requests, you
might use kahba.eachLimit or the renamed kahba.each_.
kahba.stash
The last step in fetchProductList sets a value on kahba.stash.productsByHostname holding the formatted list of products our hypothetical team
needs to buy. Any task hereafter can access the information directly on kahba.stash.
When writing an automation, it's sometimes hard to remember that normal variables are cleared with each new page. Later steps in our
automation will need this product data too, steps that run after the browser navigates away from the current page. We can't simply
set the value on a normal variable. Instead, we use the very convenient kahba.stash.
In terms of syntax, you get and set key/value pairs on kahba.stash like it's a plain object. Values set on it are persisted every time any
task finishes and the entire stash is restored when a page loads. The stash is persisted for the length of the automation's start/stop session.
We could instead persist the data in one of the Wranggle runner data stores but its methods are asynchronous
and so are a bit more trouble to use. (Though essential for storing large data we don't want cluttering our stash, or for long-lived data that
lasts beyond a single start/stop session.)
Since the last step in our fetchProductList returns { productsByHostname }, we could use some of Kahba's more advanced features
to access the information from far-distant, deeply nested workflows but they are less beginner friendly, becoming important only
for workflows intended for reuse or sharing. (We cover them in the Mastering Control section.)
Only use the stash to store serializeable data — not DOM references, functions, etc.
Scoped Stash
Should you later want to publish a workflow as a public library, you can also use a version of the stash that is scoped to a single
control flow, accessible only to it and its nested children. Never use kahba.stash in a shared/published workflow. (See scoped-data-stash.)
Catching Errors
Should our fetchProductList somehow fail, we want to give the user an opportunity to manually copy-and-paste in their shopping list, so
they can get past the problem and resume the rest of the automation. kahba.catch lets us declare a recovery workflow
that runs when there's an error, one that can ask the user to help get the automation back on track. In terms of syntax, we call it as a chained
method, eg: primaryWorkflow.catch(recoveryWorkflow).
In team-purchasing-example.js, replace the fetchProductList(runner) line with:
fetchProductList(runner)
.catch(manuallyInputProductList(runner)),
Looking at manually-input-product-list.js, we see that it returns a kahba.waterfall, one that prompts the user with a grid
input (using the Prefab API) and then formats the resulting form data to conform to the same structure defined by fetchProductList.
To try it out, you can intentionally force an error near the top of the fetchProductList waterfall. Eg:
() => Promise.reject('forced kaboom'),
(Just remember to remove once finished.)
Our manuallyInputProductList handler also introduces a new method: kahba.runUntilFinal. We'll dive into that and the related
kahba.run methods next.
For more granular error handling, see the Error Handling section in Mastering Control.
Tasks
Let's now take a closer look at where the work gets done, at the functions we write to interact with the user, the DOM, the
browser. Our code runs as normal async functions, either using a passed-in callback or by returning a promise, but sometimes we'll
need to tune a behavior, like what to do should the user navigate before the function completes. To do this, we wrap our task in one of the kahba.run methods.
In team-purchasing-example.js, uncomment the second task in the waterfall: selectDesiredStore.
This step asks the user to select a store for purchasing. Its code introduces some new Kahba concepts, relating to configuring tasks.
Interrupted tasks
The kahba.runUntilFinal method configures a task to handle the case of user navigation before the task completes. A task
wrapped in kahba.runUntilFinal will be run again on each new page, repeating until its callback or promise completes.
It's common to wrap user prompts in kahba.runUntilFinal as done in manuallyInputProductList and selectDesiredStore so the
control flow waits for the user to answer regardless of any other navigation. Although the user is perhaps unlikely to navigate during these
two particular steps, later in the tutorial we will explicitly ask the user to navigate when we handle the case of buying products from unknown stores.
Use runUntilFinal with caution. It should act to cause navigation itself, like clicking to submit a form on the content page. If
navigation might be involved, consider using a loop-related control flow (like kahba.during_) or consider investigating the
more advanced task options like maxRepeats to use as a safeguard.
Task helper methods
When a task is running, it can access the kahba.task helper methods.
Looking at src/workflows/select-desired-store.js, notice that it returns a single task and not an entire control flow. Either
is fine, but it brings up an important point. When we look at this code, we're not really sure what arguments get passed in. Is it
being used in a waterfall that is passing in data? We could go look but someone might later move it or make some other
change causing it to receive different params. Kahba offers various features to deal with this sort of headache and one approach is to
use helper methods.
Rather than including a "cb" param in the function's signature, we use kahba.task().getCallback to access its nodejs-style
callback. The callback is still present as the last argument passed in but with this helper method we can completely ignore
passed-in arguments. A related shortcut kahba.task().useCallback fetches and calls the callback in one line, eg: kahba.task().useCallback(null, someResult);
The Mastering Control section looks at Kahba's task helpers in more detail, at how they can be used to pass data/options between
workflows by explicitly marking the output from one workflow for use in some later workflow without having to use the stash or
the sessionStore.
Tasks building tasks
In team-purchasing-example.js, uncomment the next step in the top-level control flow: buildShoppingCart.
In build-shopping-cart.js we encounter kahba.taskFactorySync. The taskFactory methods are expected to build and
return another task, one that runs in its place.
When available, our buildShoppingCart uses a customized, site-specific workflow to add all of the desired items to the shopping cart. For
other sites, it falls back to a guided assistant (manually-build-cart.js) which navigates the user to each product page in
series, asking them to manually add each item.
taskFactory is useful when you want to change the structure of an automation based on runtime information. In our current team-purchasing
example, it lets us supply a workflow after we know which store the user selected.
Using a taskFactory here offers a big benefit: it lets us isolate site-specific workflows, keeping the instructions
for each e-commerce store in its own tidy, self-contained spot. This greatly simplifies the job of adding new sites and maintaining
existing ones. If we want to add support for a new store, we register it in trained-sites.js and write a populateCart function for the
new trained site.
We can also use these isolated files in smoke tests — separate automations that run these site-specific workflows against
fixture data.
The taskFactorySync method used here is a convenience method to taskFactory, using return values or thrown errors to convert a sync function
into its async equivalent. Similarly, kahba.runSync is a convenience method for kahba.run.
Or did the example site break?
Sites change and automations require maintenance. Though this tends to occur less often than you might expect, it's possible that
the example site changed since this tutorial was last updated. Rather than swapping out a realistic example with a fictitious
fixture site, we leave it to you to update any DOM selectors should any in the example break (usually a minor change to a selector) in
src/workflows/build-shopping-cart/stores/*.js.
Later we'll cover additional techniques for handling such problems, such as more granular error handlers.
Depending on the situation, an alternative to using taskFactory might be cleaner, such as delaying Kahba from starting
until the information is known (eg, from an ajax request, question to user, etc.) or rebuilding Kahba from scratch
as conditions change, as in the case of offering mini-automations on command where different Kahba sequences run as the user
clicks buttons in the UI.
Chained task options
Looking at manually-build-cart.js, we'll see some more Kahba concepts we haven't yet encountered.
To navigate, it uses runner.visitThePage, a shortcut for runner.visit that also searches passed params to find the
destination url. This step also sets the forceResult task option.
We set task options with a chained call, eg: kahba.run(myFn).opts({ forceResult: true }). Some task options offer conveniences, like
setting a task timeout or a time delay, some let us refine other behaviors like what gets passed in and out of our functions.
The forceResult option coerces the output of a function to a results object { error, result }. Normally a control flow
will end whenever any task outputs an error but the forceResult option effectively suppresses any error, letting the control flow
to continue while permitting a subsequent task to inspect its output.
We'll see other kahba.run task options in the Mastering Control section.
Better params
There's one other Kahba method in manually-build-cart.js that we haven't yet seen: kahba.conveyor. Although we'd be ok using
another kahba.waterfall here, it's worth covering the useful conveyor control flow. It is similar to a waterfall but
is tuned to pass our task functions the arguments we want.
The manuallyBuildCart workflow loops through its list of products, passing product data one at a time to another control flow, one
that visits the page then prompts the user to manually add the correct quantity to their shopping cart.
It follows a common form of working through a collection of items. Here's a more generic version:
kahba.eachSeries(taskToResolveSomeCollection,
kahba.conveyor([
(currentItem, conveyorData) => Promise.resolve({ wordLength: currentItem.length }),
(currentItem, conveyorData) => Promise.resolve({ isBigWord: conveyorData.length > 7 }),
]));
Kahba's conveyor does not directly follow any Async.js control flow interface and so it is free to add convenient Kahba-specific
features. Every task within a conveyor receives the params its parent control flow is trying to pass in (which in manuallyBuildCart is
the current productData item from the eachSeries loop) plus a conveyorData object.
In addition to receiving currentItem, each task receives a conveyorData object. It starts out empty, then each task can add
to it. Any plain object resolved by a task is merged into conveyorData, anything else is ignored.
In manuallyBuildCart, if the navigation step fails, the forceResult option will resolve that navigation step to a plain { error } object,
which the conveyor then merges into conveyorData. When prompting the user, we include a warning message when conveyorData.error is present.
If we had used a waterfall in manuallyBuildCart, we'd need to use a more advanced technique to access currentItem because
the normal/expected behavior of the Async.js-based waterfall is to pass only a callback into its first step. In the Mastering Control
section below, we'll learn how to modify tasks or control flows to receive the params we want.
Mastering Control
As we explore the remaining files in our project, we'll cover some of the more advanced Kahba concepts, ones that help you
make workflows more rugged and reusable.
Nesting
In terms of wording, let's use "task" to refer to a single step in a control flow. So kahba.series([a, b]) has two tasks: "a" and
"b". Kahba accepts not just functions as tasks, but also entire Kahba control flows.
Even without nesting, it can be challenging to work on any sort of stream, promise chain, or waterfall — anything where
the output of A is the input to B, whose output goes to C, etc. If the signature of one changes, you need to track down and
update its neighbors. Nesting adds yet another layer of difficulty and complexity, but it is also fantastically useful and
Kahba gives us the tools to keep things sane.
Consider this non-nested control flow that fetches a value from the sessionStore in its first step, upcasing the value in its
second step:
const simpleUpcase = (val, next) => next(null, val && val.toUpperCase());
kahba.waterfall([
() => runner.sessionStore.get('keyForSomeExistingData'),
simpleUpcase,
]);
If the first step fetches the value "hi" from the sessionStore, the result of the waterfall is "HI". Should we use it inside another
control flow, the parent sees it as a single task, one that resolves to "HI".
But now our project requirements change and we need to do something more complicated than upcase. We replace it with another control
flow that introduces a param-passing challenge:
const fancierTask = kahba.waterfall([
whatToDoHereOhNo,
]);
kahba.waterfall([
() => runner.sessionStore.get('keyForSomeExistingData'),
fancierTask,
]);
We originally had a signature we liked: (fetchedValue, next) => {} but now, nested, whatToDoHereOhNo has the default signature
of a waterfall, where only its callback is passed into the first step. How to get the value fetched from the session store?
Kahba offers a few solutions to this challenge, letting us write tasks that can access the information we want, keeping our workflow logic
relatively isolated even when deeply nested.
Modifying task signature
We can tell Kahba to expand what gets passed in to our function using the deepParams task-level option.
At the top of the team-purchasing-example.js entry point, change fetchProductList's require from fetch-products.iteration-1.js to
fetch-products.iteration-2.js.
This updated fetchProductList_2 workflow contains examples of most of the remaining Kahba concepts left to this tutorial. The revised version replaces
the hardcoded CSV path with a user-set URL, accepting both a Github-rendered CSV cover page or a link to any raw CSV file. It also adds
some polish and performance tuning.
Look for a nested kahba.waterfall at around the middle of conveyor control flow. It performs the XHR request using the resolved csvUrl then
parses and formats the response. To stay consistent with the Async.js waterfall, the waterfall's first task is not passed any
data, only a callback, but we need that param.
We tell Kahba to include pass in that param by wrapping our function in kahba.run and setting the deepParams task-level
option using a chained call, eg ourTask.opts({ deepParams: 2 } ). When deepParams is set to 0 only its callback is passed
in, when set to 1, it receives only the arguments its control flow would normally pass, when set to 2, arguments from its
parent control flow are prepended to the signature, and so on.
We can apply task options to all direct/non-nested/immediate functions in a control flow using subtaskOpts. We use it on
our conveyor for bettor isolation, setting theConveyorWorkflow.subtaskOpts({ deepParams: 1 }). The conveyor
control flow is optimized for the nested case (eg, kahba.eachSeries(someCollection, someConveyor), using a default deepParams
of 2. Since nothing is passed into fetchProductList, we'd be ok with the default but since we're not expecting anything and
the conveyor is the top level control flow in our file, it's best to explicitly set it to 1.
The file shows some alternative techniques in comments. In particular, it shows how a scoped stash could be used. Using the
main kahba.stash is similar to a global variable. It's important to avoid cluttering that space when writing a workflow intended
for reuse or sharing. A scoped stash is isolated from the main kahba.stash, only the control flow that first declares it and
its nested control flows can access it.
Helper methods
Your function can explicitly access arguments passed by parent control functions by calling task helpers.
The "this" context of your running task is a task helper object by default. As that will frequently be masked (such as from
the use of () => {} function notation rather than function() {}) you can access it by calling kahba.task().
kahba.task().getArgumentsStack returns all arguments from all nesting generations without callbacks, an array of arrays. The
current function's arguments array is in index 0, its parent's in 1, and so on. getArgumentsStack is especially handy when debugging, so you
can see all params accessible to a task. A related helper, getTaskDataByGeneration, returns the arguments array for the single
generation you specify.
kahba.task().findNestedArgument searches every nested generation from closest to most distant using a passed-in match function. It
loops through the arguments stack, optionally looking at either all or just the first argument per generation. What makes findNestedArgument worth
mentioning is its usefulness in completely avoiding the need to count nesting generations. For example, if an early workflow resolves Promise.resolve({ dataForLater }) we can grab that argument in a
deeply nested control flow with something like kahba.task().findNestedArgument(param => !!param.dataForLater).
When accessing that csvUrl in fetchProductList_2, the commented findNestedArgument argument might look the least appealing
at first glance, but it has its place. When workflows are spread across multiple files or if you are writing a workflow that
you intend to publish, you can use it to explicitly declare data as options for a specific workflow.
Calling kahba.task() returns the task helper for the last task function started in Kahba. When using a parallel control flow (like kahba.parallel_, kahba.race_, etc) you
might get the wrong task helper if you make the call in a later tick (eg, in a setTimeout, in a user prompt callback, etc.) If using
such a delayed situation, set it on a local variable early (eg const taskHelper = kahba.task()) and use or pass the correct reference.
It returns the latest task helper, so take care when using parallel control flows (like kahba.race_) since the "latest" will be the last one started. Set it on a local variable. Eg: const taskHelper = kahba.task();
Control flow callbacks
Kahba control flows accept an optional callback as their last argument, a sync function that follows the conventional (err, ...results)
signature. When nested, the parent control flow treats the child control flow as a single, normal task, one that resolves using these same (err, ...results)
arguments.
Providing a callback function to a control flow lets us override what gets passed along to the parent control flow. If a non-array
(or nothing) is returned then the default [ err, ...results ] is used. This gives us the opportunity to inspect the results of
a control flow and introduce an error [ someError ], suppress an error [] or [ null, someDefaultResult ], or modify result data.
Consider this nested structure:
kahba.mapSeries(someTaskFetchesSomeCollection,
kahba.conveyor([
doesStuff,
], (err, conveyorData) => {
if (err) {
reportItToUser(err);
return [ null, someDefaultResult ];
}
}));
The above mapSeries runs the someTaskFetchesSomeCollection task first then loops over its results, passing each item to its
waterfall. The waterfall's callback suppresses any error encountered, reporting the problem to the user and overriding the
result of the current iteration with someDefaultResult. If no error is present, it implicitly uses the same [ err, conveyorData ]
default. The parent control flow, the outer mapSeries, sees it in all cases as a task finishing successfully.
We could also provide callbacks to the other control flows in the example (someTaskFetchesSomeCollection or the outer mapSeries) if
desired. For example, if we only cared about the max/best value of that topmost mapSeries, we might use a callback that overrides
the final result: return [ null, _.max(_.flatten(result)) ]
In fetchProductList_2, a callback extracts productsByHostname from the conveyorData object, formatting it to be consistent
with the original fetchProductList. The last step also sets the value on the main kahba.stash because the less sophisticated
selectDesiredStore step expects it.
More Error Handling
An error in a control flow will, without handling, propagate up to the topmost Kahba control flow, finishing it as well. Sometimes this is desirable, as
when a user clicks Cancel in selectDesiredStore when we want to display a goodbye message and exit. Sometimes it is undesirable, as
when a single product fails in buildShoppingCart and we want it to continue on to the next product.
Using a callback to override the output of a control flow gives us a granular degree of control, letting us inspect any error and
suppress it or replace it, perhaps adding a "userMessage" attribute before letting it propagate.
Remember that callbacks are always sync functions. To handle an error with an asynchronous function or control flow, use the
chained primaryWorkflow.catch(recoveryWorkflow) as covered earlier.
Also remember, if you want to suppress an error on a single task, wrap your function in kahba.run and use the chained forceResult option.
Throwing errors
Besides catching errors, it's often just as important to throw them. Let's look at the error handling in fetchProductList_2.
This updated version replaces the hardcoded URL with one input by the user. (To to edit this URL when running the automation, click
the Settings action in the popup's top-right corner.) A lot could go wrong: the user might provide a malformed URL (especially
since we didn't add validation to the form), the CSV file itself might be missing, the fetched CSV contents might fail to
parse, etc. To improve the quality of the automation for the user, we apply a number of checks to the workflow:
After retrieving the user's csvUrl from prefab.userSettings, we do a rough check to see if it ends with .csv. If not, our
function completes with an error by rejecting a promise, following a convention for errors of { errorCode, userMessage, anyOtherDetails }. We
could have also used the Node.js convention of returning theerror as the first param of its callback. If the URL check looks
ok, we set its value on the scoped stash in case that's the approach you decide to use to access the value when making the XHR request (described early.)
The next step uses kahba.if to see if the URL looks like a Github cover page. If so, it branches down a nested workflow
that navigates to the cover page and then inspects the DOM to resolve the direct URL to the raw CSV file.
When using a Github cover page, the _workflowToExtractCsvUrlFromGithubPage (in a function lower down in the same fetch-products.iteration-2.js file)
is similar to the original fetchProductList. Instead of using kahba.wait in a separate task as we did before, it sets it as
a wait option on kahba.visit which has the minor advantage of introducing tolerance to client-side redirects involved in
navigation.
The abort option, provided the same type of selectors/conditions as wait, tells kahba.visit to raise an error immediately should
the conditions pass. So if the browser navigates to a Github error page, perhaps because the CSV link is to a private repository,
we won't make the user wait for the wait to time out. (Though not shown here, runner.click and runner.wait also
offer options for aborting/failing early.)
Also on the topic of timeouts, consider offering users an option to abort any wait, implemented using a kahba.race_ control flow
that races the navigate/click/wait against a user prompt to skip ahead.
As another minor performance improvement, the next step checks if Github was able to render the contents of the CSV as a table. If not,
it outputs an error time using the minor kahba.error shortcut method, to save the user from waiting while it would otherwise
fetch a file that would fail to parse.
Specialized methods
The following methods, ones we didn't cover in this tutorial, might be worth skimming:
-
kahba.ready when you want to control when Kahba starts. Otherwise, Kahba starts automatically on every page load, a tick after
your automation script is evaluated.
-
kahba.pause to pause a long-running automation, so it can be resumed later rather than stopping the automation and starting over
from scratch. (NOTE: Wranggle will likely add this to the Prefab API, simplifying it to a command to display it in the UI or
not, handling the UI and Kahba calls for you.)
-
kahba.data helps retrieve data from the stash and elsewhere, for use with collection methods.
Miscellaneous tips
Debugging
Here are some debugging techniques to consider as you work on automations:
-
In Google Chrome's Developer Tools window, switch the context window in the Console from "top" to "Wranggle". This is the
content script window where your automation code runs. From here, you can access wranggle.runner. For example, if you suspect that
one of your functions isn't using its callback or resolving a promise, you can use the kahba.task helpers to inspect it.
-
In Developer Tools, make sure "Preserve log" is checked so console output is not cleared on navigation.
-
Many tasks and the kahba.run wrappers accept a debug option, telling it to log information about its state and params to the console. Eg, myTask.opts({ debug: true }). If
adding it to more than one, consider giving it a label to better find it in the console: myTask.opts({ debug: 'nooooo... why oh why?' }).
You
might notice a "storageKey" in its output — it is Kahba's internal id for that runtime instance of the task and is mostly
incomprehensible, but calling kahba.task().getStorageKey() in a task will return the same corresponding id, which is on occasion
useful for matching to task-level debug output.
-
If you're deferring the Mastering Control section for later but find that your function is not passed an argument you want or
is annoying you by passing in extra arguments, you may need to read the Nesting section or inspect
what's being passed with task helpers. (Eg: kahba.task().getArgumentsStack() and kahba.task().getTaskDataByGeneration(2).)
-
When working on a task deep inside some long process, consider creating a temporary top-level workflow that passes fixture data
into the work-in-process workflow, so you don't need to repeatedly run through the entire automation.
jQuery & DOM
When providing sizzle/jquery selectors to Kahba methods (like runner.wait, runner.click) a couple tips:
-
remember to use jQuery's :visible filter liberally. (Present yet hidden elements are a surprisingly common pitfall.)
-
use the Wranggle-specific NOT ("!") prefix in selectors to require not-present. (A non-standard selector.) For example, to wait for
a modal to close, you might use: runner.wait('!.modal:visible')
See also: the Wranggle Guide on Working With The DOM.
Limitations
Take a look at the Developer Preview notes. In particular, the security section — as of Developer Preview 1,
some of the planned security features/layers have not yet been implemented.
Wranggle does not include functionality to support interactions with Flash or HTML canvas content. Should a site not offer API access
or some workaround, you might look into using a visual/optical recognition API in your automation, but Wranggle does not anything directly.
with one such as Google Sheets, a canvas-heavy site, consider having your automation make calls to their API if available instead of manipulating
the page directly in the browser. Wranggle does not offer its own APIs for visual/optical recognition but
Side-note on Google Sheets
Google sheets is potentially a very useful service that lets teams jointly maintain automation data but it is a canvas-heavy page, making direct
interactions difficult. It might be possible to interact in-page by simulating arrow and other keys and looking at the current cell value
but a far better solution is for your automation to make API calls to it. Alternatively, Sheets has
a Canvas-free "Publish to web" feature but the page it produces is read-only and updates are time delayed. Or consider using
a non-Canvas/non-Flash service. (eg, AirTable)
Serializeable data
Kahba serializes and stores the params passed between tasks, so they can be used in later page loads. As mentioned earlier, your functions
should only resolve data that can be de-serialized, and
not functions, DOM elements, etc.
Also keep in mind the size of the data being passed. For large ones such as screenshots/images, it's better to get/set the
data using the sessionStore rather than passing the data in a control flow. Kahba does some clean up but as of Developer Preview 1 has
not yet been fully optimized so such information might be moved around (and duplicated ) with unnecessary frequency, potentially
becoming a memory or performance problem.
Finished!
Perhaps you want to: